Then edit /etc/nginx/nginx.conf file and modify this directive:
large_client_header_buffers 4 8k;
by
large_client_header_buffers 4 16k;
Execute nginx -t and if no error, restart nginx:
systemctl restart nginx
If that doesn’t work, instead of 16K you could change it to 32k, also, in the same file you could change client_header_buffer_size 2k; to something like client_header_buffer_size 8k;
This script has the comment # Manual upgrade script from Nginx + Apache2 + PHP-FPM to Nginx + PHP-FPM
And I would like to upgrade from Nginx + PHP-FPM to Nginx + Apache2 + PHP-FPM
I understand your concern but I’m trying to help based on the info we get. Also, keep in mind that there are no changes on main nginx conf but your sites have been rebuilt during the upgrade, don’t know if that modified something to your sites.
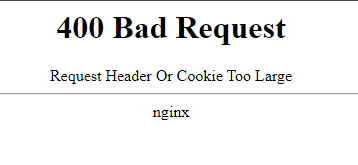
I changed the worker_connections, and then the error went back to 400 Bad Request Request Header Or Cookie Too Large.
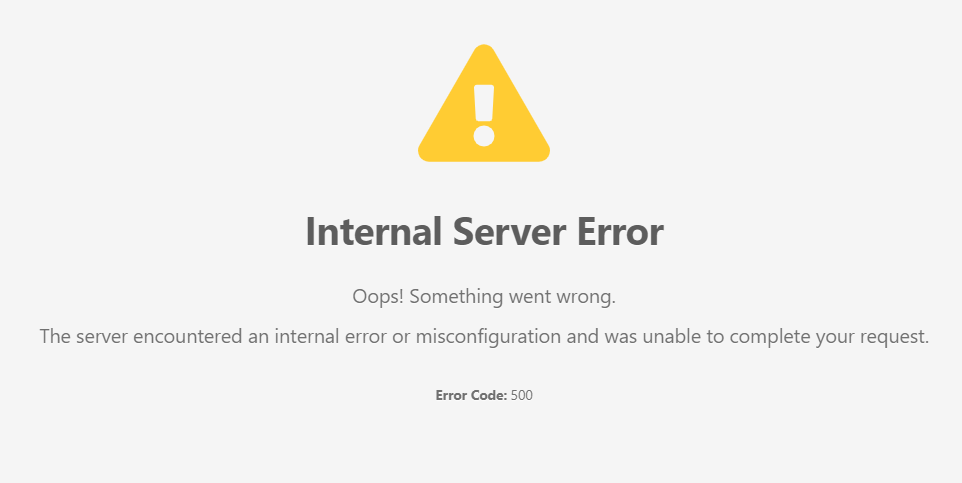
So I changed the large_client_header_buffers again, but now to 32k and the 500 error came back.
I don’t think it’s my application, I also checked and it didn’t have any changes, like the Webmail that uses Roundcube, it issues the same error. Any other suggestions?
As in the other topic, it seems that this error happens when HestiaCP is updated and for those who have already migrated from Apache + Nginx to Nginx only, I don’t know if it’s related.
#----------------------------------------------------------#
# Verifications #
#----------------------------------------------------------#
if [ "$WEB_BACKEND" != "php-fpm" ]; then
check_result $E_NOTEXISTS "PHP-FPM is not enabled" > /dev/null
exit 1
fi
if [ "$WEB_SYSTEM" != "apache2" ]; then
check_result $E_NOTEXISTS "Apache2 is not enabled" > /dev/null
exit 1
fi
nginx: [emerg] open() “/etc/nginx/conf.d/domains/webmail.mydomain.com.ssl.conf” failed (2: No such file or directory) in /etc/nginx/nginx.conf
Before i got this:
nginx: [emerg] the shared memory zone “mydomain.com” is already declared for a different use in /etc/nginx/conf.d/fastcgi_cache_pool.conf:1
nginx: configuration file /etc/nginx/nginx.conf test failed
also nginx dissapeared from service overview in backend. after changing nginx conf file.
Edit: after adding WEB_SSL_PORT=‘443’ and WEB_SERVER=‘nginx’ to hestia.conf, nginx is active as webserver again.
Im pretty sure it was due to me migrating from apache2+phpfpm to nginx+phpfpm a month ago. This morning only one domain failed and it was due to nginx proxy cache still active on the domain (before i restarted nginx and it failed). After disabling proxy cache nginx started again.
So it seems i made a mess after i deleted the cache folder contents.
This fix has fixed only the sites (and requested me to manually set again the Nginx template for each single site). Is there a quick fix for the webmail?