Hi everyone,
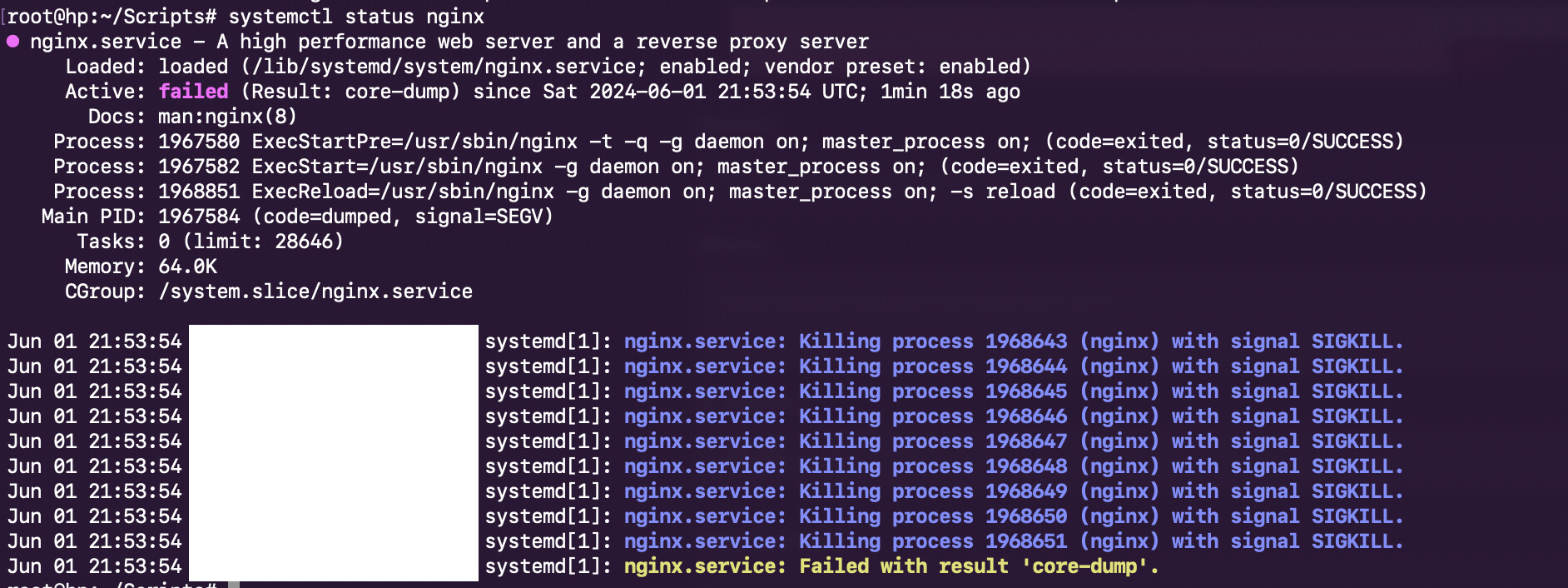
I’ve just run my first website backup and I see that Nginx failed with the following (taken from syslog):
May 22 07:33:02 hp systemd[1]: Reloaded A high performance web server and a reverse proxy server.
May 22 07:33:02 hp systemd[1]: Reloading Dovecot IMAP/POP3 email server.
May 22 07:33:02 hp systemd[1]: Reloaded Dovecot IMAP/POP3 email server.
May 22 07:33:02 hp systemd[1]: Reloading LSB: exim Mail Transport Agent.
May 22 07:33:02 hp exim4[667270]: * Reloading exim4 configuration files
May 22 07:33:02 hp systemd[1]: nginx.service: Main process exited, code=dumped, status=11/SEGV
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565812 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565813 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565814 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565815 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565816 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565817 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565819 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565821 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565822 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565812 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565813 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565814 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565815 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565816 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565817 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565819 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565821 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Killing process 565822 (nginx) with signal SIGKILL.
May 22 07:33:02 hp systemd[1]: nginx.service: Failed with result 'core-dump'.
May 22 07:33:02 hp exim4[667270]: ...done.
May 22 07:33:02 hp systemd[1]: Reloaded LSB: exim Mail Transport Agent.
May 22 07:34:01 hp CRON[667738]: (admin) CMD (sudo /usr/local/hestia/bin/v-update-sys-queue restart)
May 22 07:35:01 hp CRON[667767]: (root) CMD (command -v debian-sa1 > /dev/null && debian-sa1 1 1)
May 22 07:35:01 hp CRON[667768]: (admin) CMD (sudo /usr/local/hestia/bin/v-update-sys-queue backup)
A simple systemctl restart nginx fixed the issue, but does anyone of you can think of a reason why this happened in the first place?