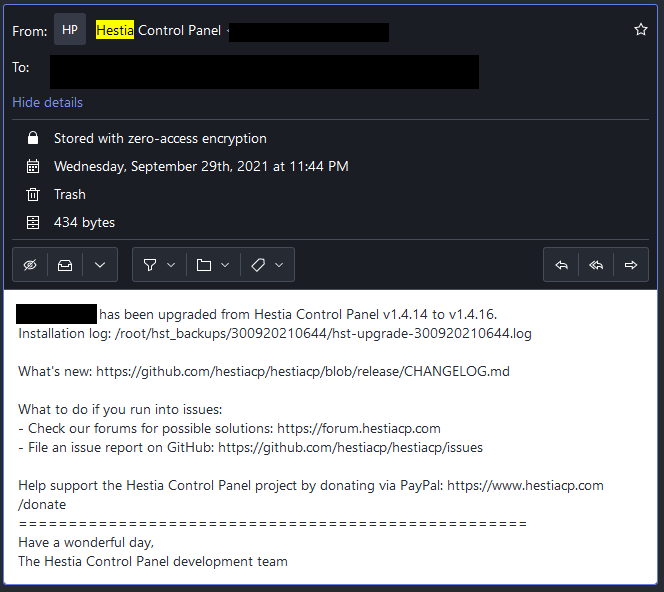
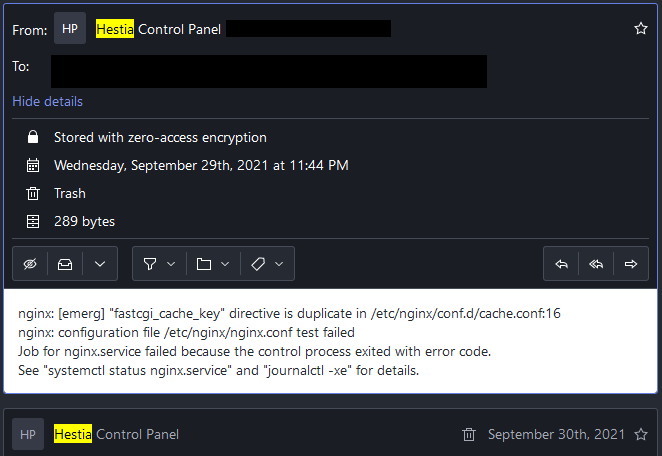
One of the updates installed a new /etc/nginx.conf, which caused a conflict with my configuration. As a result, NGINX didn’t restart and all my sites were down for several days until I noticed the error.
Is there any way to add a configuration check (e.g. nginx -t) before trying to restart NGINX after an update? That way, if there’s a conflict, the webserver will continue to run with the old configuration while giving me a chance to correct any errors.
Nginx update is not arranged by Hestia and there for we are not even able to detect if Nginx restart. Also during this update the software will ask you to keep the current version or replace it with the new version… Always say keep the current version.
In apt (Debian’s package management), I have NGINX held so it can’t update. I have some custom modules so if I accidentally updated NGINX somehow, I’d know because I’d have to recompile the modules to be compatible with other versions.
At this point, I have no other suspect except Hestia.
At this point, I don’t know who updated /etc/nginx/nginx.conf. NGINX is held in the package manager and any updates would immediately break because the modules aren’t compiled for the right version.
I spun up a test version of Debian 9 on a VM and /etc/nginx/nginx.conf is totally different than the one running Hestia.
Regardless, I still want a configuration check before Hestia attempts to restart the webserver. I want the updates to fail safely and keep my sites running.
Both the upgrade and NGINX restart failure occurred within a minute.
And the duplicate directive, I originally wrote it in /etc/nginx/conf.d/cache.conf. It was a surprise to me when I found similar directives in /etc/nginx/nginx.conf.
I can only speculate that Hestia did something during the upgrade to change /etc/nginx/nginx.conf.
No. You didn’t read the error message closely enough. You cannot have duplicate fastcgi_cache_key directives.
I guess this also means Hestia changed /etc/nginx/nginx.conf. I really wish you’d give people the benefit of the doubt.
Regardless, Hestia attempted to perform a webserver restart. My feature request is to have Hestia perform a configuration check before attempting to restart the webserver.
You did an upgrade from 1.4.14 to 1.4.16, also hestia doesnt touch usualy the nginx.conf, just in rare cases like with the release of new features like we did in 1.4.0 - but in that case, it seems not to be related to your problem.
There has been already some improved validation steps for service restart handling, but its still work in progress.
I can’t tell you where it came your issue from, but in that update case (1.4.14 to 1.4.16) it was clearly not hestia - expect the nginx restart which showed up the issue.
About the “…went days offline”-part I would suggest to use a monitoring service like statuscake.com or uptimerobot.
Unless the server was never restarted since 1.4.0 release / When the update was applied nginx should all ready be off-line for a very long period. As after 1.4.0 was installed the server was already restarted.
It is always smart to enable monitoring for your server with the use of nagios or any other monitor tool.
There plans to improve the restart and allow the system to go back to the last template used (or default) template used.
Also for LE, creation / deleting / modifying web settings nginx is already restarted regullary …
I agree that the changes to nginx.conf may not be directly related to 1.4.16 update. Hestia may have implemented those changes in previous upgrades.
However, Hestia trying to restart the webserver without checking the configuration is an issue. A simple ‘nginx -t | grep successful’ would’ve detected the issue.
Yes, that sounds like a good idea. Debian being rock solid and my VPS host having great uptime lulled me into a false sense of security. I honestly didn’t think Hestia would be the one to cause a DoS.
No, that’s not true. I originally installed Hestia 1.4.1 or 1.4.2 and I specifically implemented fastcgi caching because it wasn’t present in the current NGINX configuration.
To be honest, I don’t really know which version of Hestia I installed. According to the notifications, the earliest update that I see is 1.4.3, which is why I assumed I installed 1.4.1 or 1.4.2. But I may have installed an earlier version.
But I do know that at the time of installation, Hestia didn’t have fastcgi cache enabled because I had to manually create the config files.
Regardless, my issue is that Hestia made changes to a core NGINX config file, attempted to restarted the webserver, and it failed. It doesn’t matter whether Hestia made those changes several versions prior or just then. It just matters that at the time of the webserver restart, Hestia didn’t make any attempts to see whether the configuration was good.
I’d like to see Hestia do a configuration check before attempting to restart the webserver. If the configuration check fails, abort the webserver restart and send an email warning that there’s something’s wrong with the webserver config. That way, the webserver keeps running, no sites go down, and the administrator has time to take corrective action.