What the title says. I had helped you guys with fixing the PHPPGAdmin integration back then (maybe Jaap remembers), and ever since then, it and PHPMyAdmin worked just fine. However, after maybe the recent or one of the previous updates, both now cease to work, and I cannot figure out why. Every time I try accessing them, they now lead to a “Bad Gateway” page with the “502” error. I also am not sure which log file to check (if any), as there’s simply too many strewn across the system. Does anyone have any suggestions to this?
Hello @LokeYourC3PH,
Things that you could check:
Try to get the exact error from logs:
grep -ri 'bad gateway' /var/log/
Check fastcgi_pass conf:
grep -ri 'fastcgi_pass' /etc/nginx/
You should see that phpmyadmin.inc and phppgadmin.inc are using 127.0.0.1:9000
Check if there is something listening on port 9000:
netstat -ptan | grep -i listen | grep ':9000'
You should see a php-fpm process, to check the entire command of this process, get the pid from above command and:
ps -ef | grep herethepid
You would view the right php-fpm version that is listening in that port and you could view the systemd status of that php-fpm service:
systemctl status here_the_php_service_name
Example if you get php-fpm 8.2
systemctl status php8.2-fpm.service
Also, check which php-fpm version has configured the listen directive for port 9000:
grep -r ':9000' /etc/php/
With this data you could start to figure out what is wrong in your server.
Thanks a lot, will look into everything you’ve mentioned ![]()
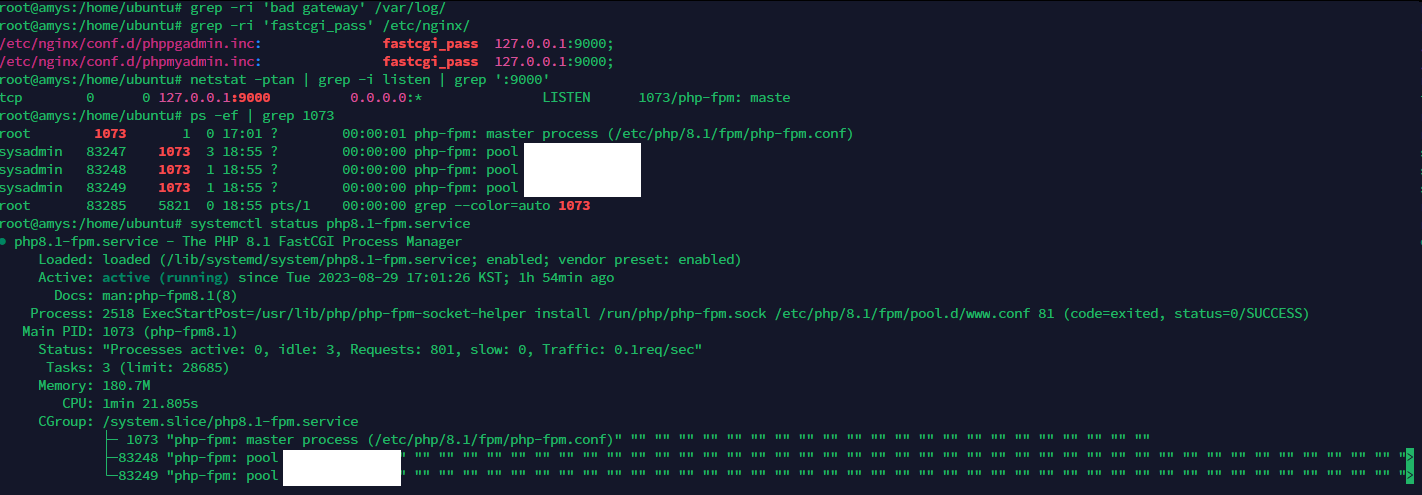
According to all of the commands, absolutely nothing is wrong at all. Everything runs fine, is properly configured, and there seems to be nothing about “bad gateway” in any log that is grep’ed. Any other idea?
EDIT: Oh and, I had disabled/removed PHP 8.2, as I have it all run on PHP 8.1 anyways, but it was the one running on Port 9000, not 8.1. However, after doing so, nothing has changed (rebooted the entire system as well, so yea).
Since recent release, php 8.2 is the default for Hestia so maybe you shouldn’t remove it. Also, I don’t understand what you did.
Edit: I forgot to say that you should try to reproduce the error before grepping the logs… or use zgrep instead of grep in case the error is in a gzipped log.
2nd Image:

Search for Connection refused in logs:
grep -ri 'connection refused' /var/log/
Or by phpmyadmin:
grep -ri 'phpmyadmin' /var/log/
You must find the error to know what is going on.
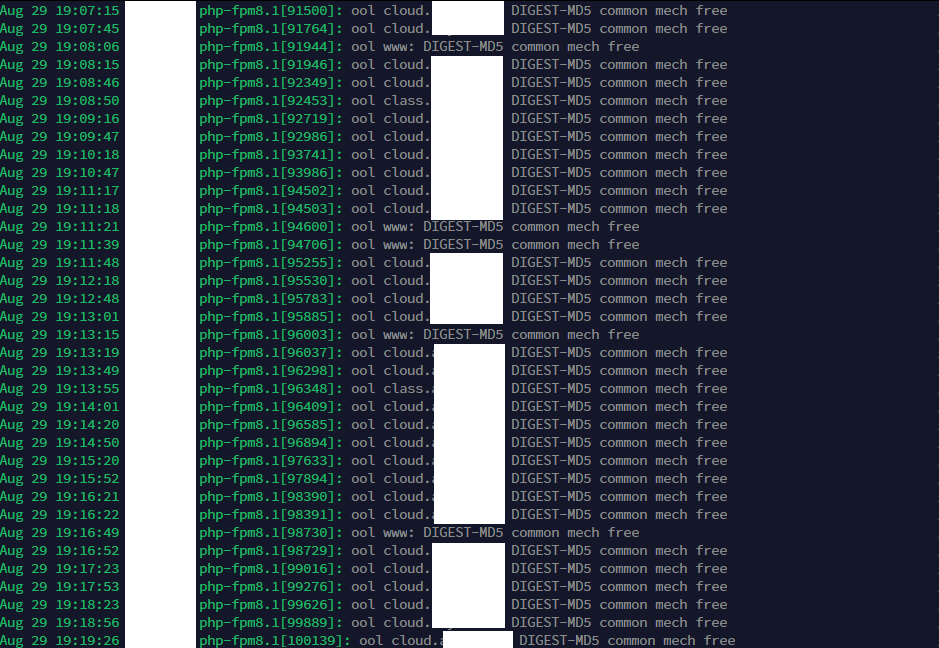
So, according to the 2nd search, I found the following (I also opened the site once more on purpose to have an exact time stamp to recognize in the file):
EDIT: After doing “grep -ri -E ‘phpmyadmin.*19:11|19:11.*phpmyadmin’ /var/log/”, I found the same result as above only based on the timestamp. This to me confirms that this must be the issue, but I have no idea what to do with this next.
Check php-fpm service just in case there is more info there:
journalctl --no-pager -u php8.1-fpm.service
I don’t know what could be the issue, maybe a conf error, memory, or max files limits, wrong perms…
Just in case, try to raise memory_limit directive in /etc/php/8.1/fpm/php.ini file, maybe that could help.
Remember to restart the service after the change.
systemctl restart php8.1-fpm.service
If that doesn’t help, lets see whether another community member has some ideas to debug/fix the issue.
I doubt that 16GB isn’t enough (I had it on 16GB for a while due to plenty of services running at once):
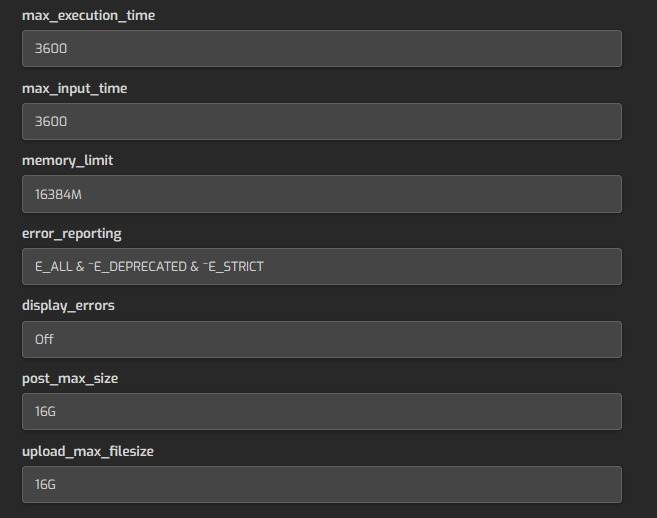
Well, in any case I hope Jaap as a better idea, he knows PHPMyAdmin really well as we worked on it a while ago.
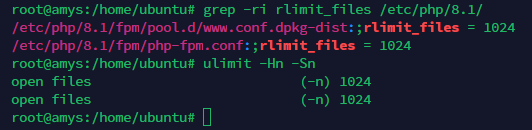
Do you have some rlimit configured in php?
grep -ri rlimit_files /etc/php/8.1/
and what are the limits for nofiles defined for your root user?
ulimit -Hn -Sn
Let’s see if @eris can help here ![]()
Here you go ![]() :
:
There is no reason to have 16GB memory limit. It will mean for every process max memory for 16gb …
https://bugs.php.net/bug.php?id=81664&edit=1
Try to decreases the limits a lot…
1 Like
Hi Jaap. Well the 16GB limit isn’t the problem here though. And I had it at 4GB before, but then Nextcloud (which is under heavy load sometimes) was slowing down and stalling. Also, what is the link you sent me supposed to be for? The issue I am having has to do with PHPMyAdmin, which started failing after upgrading HestiaCP, so it’s clearly an issue introduced by HestiaCP.
And I lowered it back to 4096MB now, but again, that isn’t the problem here. The issue with the “Bad Gateway” for PHPMyAdmin is the same.
Ok, rlimit_files is not defined so it is using limits defined in system and to me, 1024 seems very very low.
You could try to raise limit for user root and the for php8.1-fpm systemd service.
Edit /etc/security/limits.conf
And add or modify this:
root hard nofile 65000
root soft nofile 65000
Save the file, logout and login again with root and check ulimit to see whether it has changed.
Now, check the pid of php8.1-fpm
systemctl status php8.1-fpm.service | grep -i 'main pid'
With that pid, check the current limits for that process.
cat /proc/herethepid/limits | grep -i 'open files'
Now edit the service to modify nofile limits.
systemctl edit --full php8.1-fpm.service
And add this LimitNOFILE=45000 below [Service]:
[Service]
LimitNOFILE=45000
Save the file and restart the service.
systemctl restart php8.1-fpm.service
Get the pid again and check with cat /proc/herethenewpid/limits whether the max open files limit has changed.
Also, test again phpmyadmin, maybe it would help… who knows
Here you go, made all the changes:
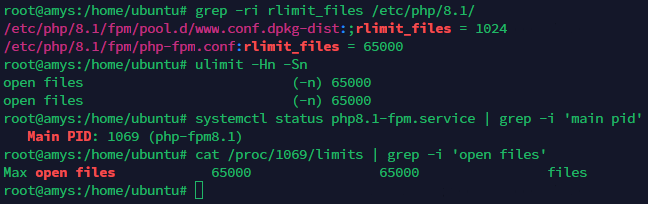
But yeah, issue persists. Like I said, it was introduced with some HestiaCP change in the past couple of releases. No idea which one though as I don’t go around testing every single feature after each new release to see if it stopped working. But anyhow, thanks for the system improvement tips, they’ll help for sure.
That being said, when opening PHPMyAdmin, I get: Bad Gateway 502
It might be worth noting I use Cloudflare, but it has never been an issue previously either. Some HestiaCP update/release caused this, and it has either to do with NGINX or Apache2 (I am using Apache2 as the web server, and NGINX as the proxy).
EDIT: Well great, I am now not allowed to post anymore for 17 hours because of stupid rules for new users, cool ![]()
So I will just have to keep editing this post for the next 17 hours, awesome.
Upgraded you user level a bit …